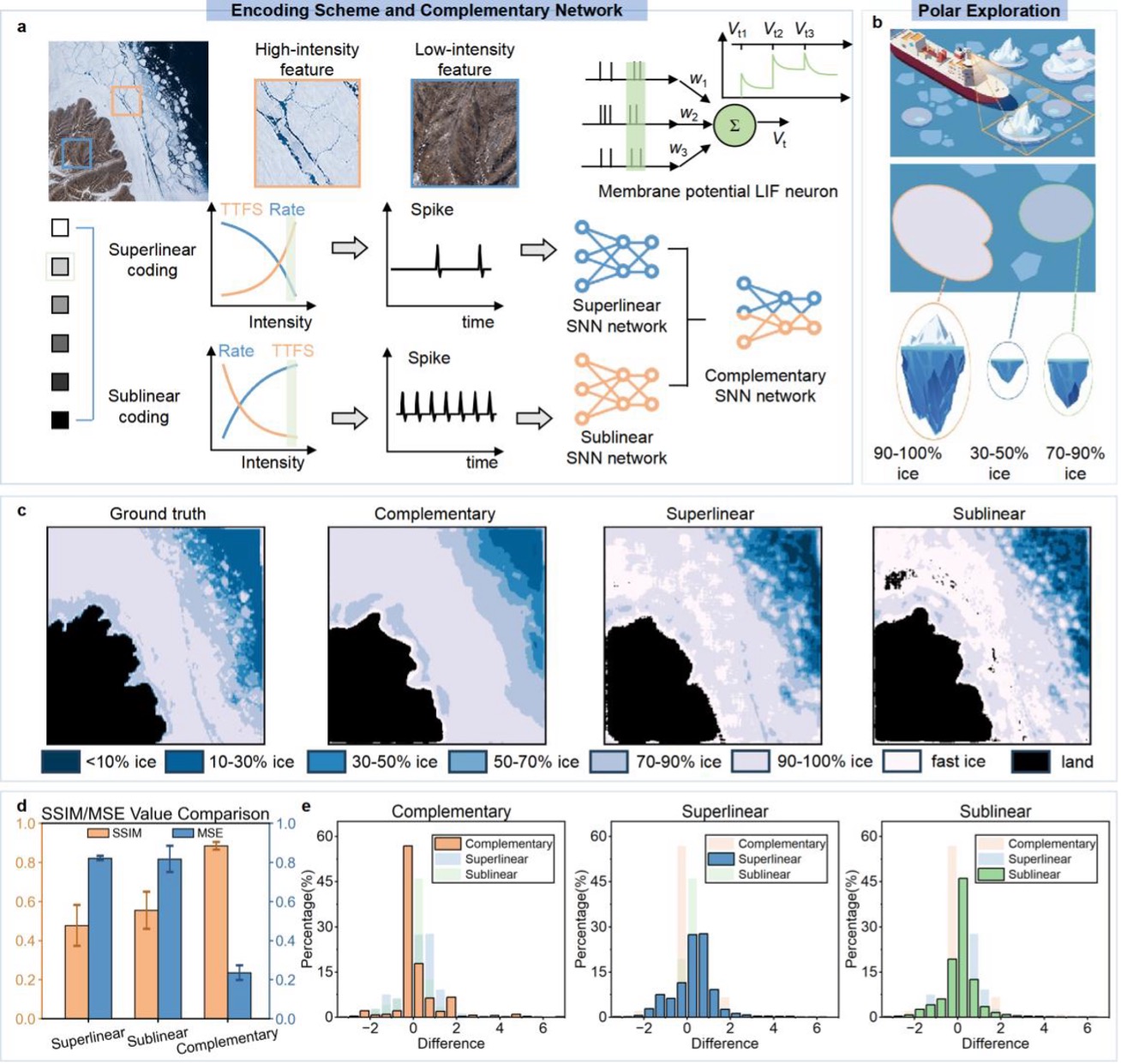
Spiking Neural Networks (SNNs) are an emerging type of neural network structure. Due to their spike-based encoding of information, the traditional neural network's multiply-accumulate (MAC) operations can be replaced by more efficient accumulation operations, making them highly suitable for resource-constrained edge devices. In the past, SNNs were typically small-scale fully connected networks, which greatly limited their application scenarios. However, recent developments in neuromorphic computing have enabled the spike-based adaptation of proven effective network architectures in deep learning fields, such as ResNet and Transformer networks, which greatly expands the application scenarios for SNNs. SNNs require dedicated neuromorphic hardware to achieve maximum energy efficiency, yet existing neuromorphic processor architectures are primarily designed for small-scale fully connected networks, which constrains the performance of deep spiking neural networks in practical deployment.
A recent contribution from the CenBRAIN Neurotech, published in the IEEE Journal of Solid-State Circuits (JSSC). In this paper, we introduce an energy-efficient unstructured sparsity-aware deep SNN accelerator with 3-D computation array.
Chaoming Fang, a Ph.D student from CenBRAIN Neurotech is the first author of this work, Dr. Mohamad Sawan and Dr. Jie Yang are the corresponding author.
This work was supported in part by the STI2030-Major Projects under Grant 2022ZD0208805, in part by the “Pioneer” and “Leading Goose” Research and Development Program of Zhejiang under Grant 2024C03002, and in part by the Key Project of Westlake Institute for Optoelectronics under Grant 2023GD004.

Abstract
We designed an energy-efficient deep spiking neural network accelerator chip that leverages a three-dimensional computing array and unstructured sparsity acceleration. This design has undergone a series of optimizations targeting cutting-edge spiking transformer and spiking ResNet network structures. It has been validated through tape-out with the 40nm CMOS, achieving an energy efficiency of 0.078 pJ/SOP, while also achieving a 77.6% accuracy rate for ImageNet image recognition, which is the best level among similar works.
Research Highlights
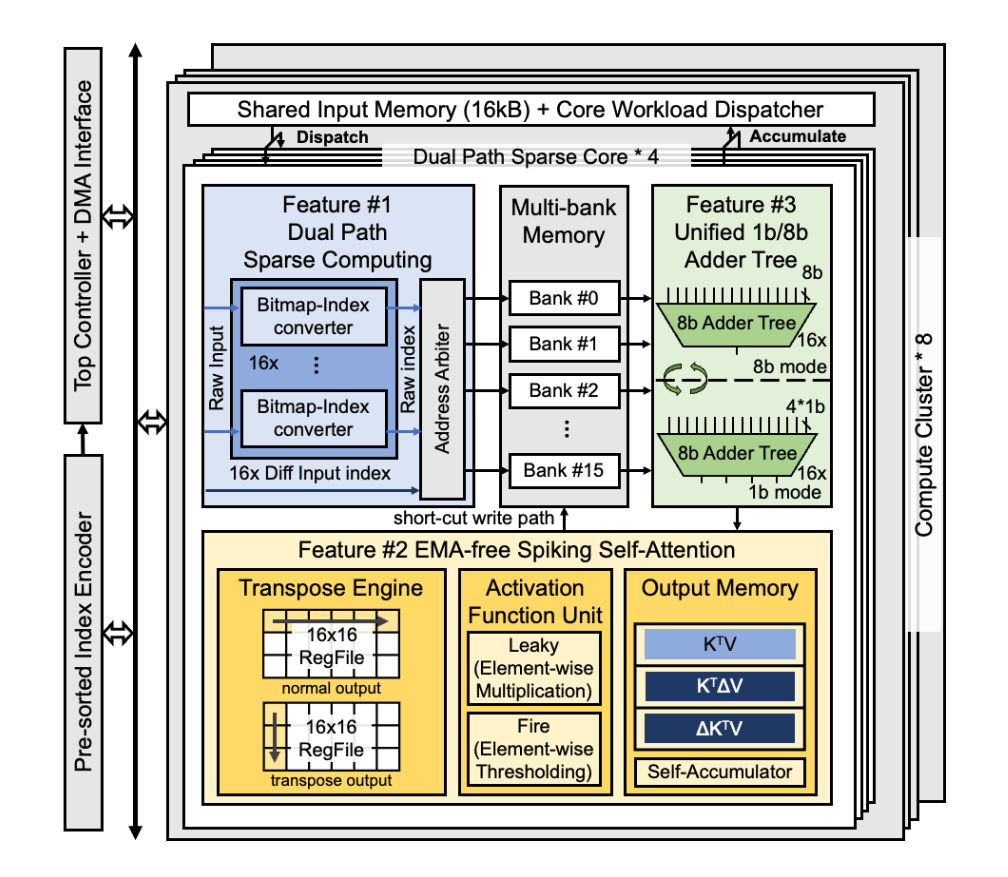
1. A three-dimensional computing array that builds upon the traditional accelerator's "input channel-output channel" two-dimensional computing array. By targeting the characteristics of SNNs, we have expanded the parallel dimension of time steps, allowing computations at different time steps to be completed in parallel. This avoids the repeated reading of weight values across different time steps, significantly reducing the energy and time overhead of off-chip memory access.
2. In response to the high input sparsity characteristic of SNNs, we have designed an unstructured non-zero value extraction circuit that can load multiple unstructured non-zero "spike-weight" pairs in each clock cycle, while also saving power consumption and latency associated with processing sparse spiking inputs.
3. For the newly emerged spiking convolution, QKV matrix generation, and spiking self-attention operators in deep spiking neural networks, we have designed an adaptive scheduler. This scheduler includes an inter-core memory router to avoid bank conflicts, a bidirectional data compressor to accomplish the transpose operations required in QKV matrix generation, and a sparse self-attention zero-skipping module to predict and skip the computation of positions in the self-attention output that are zero.
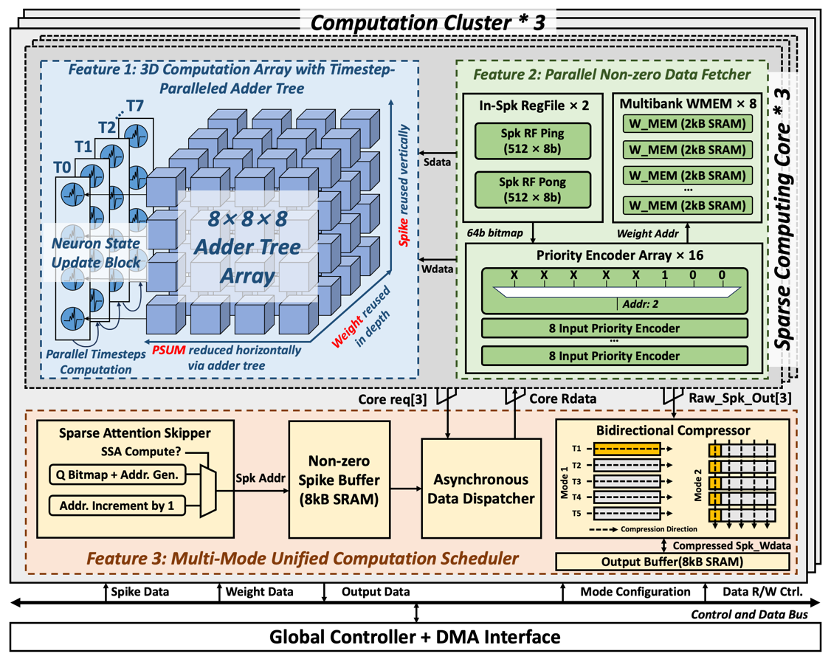
Fig.1. Overall architecture of the chip.
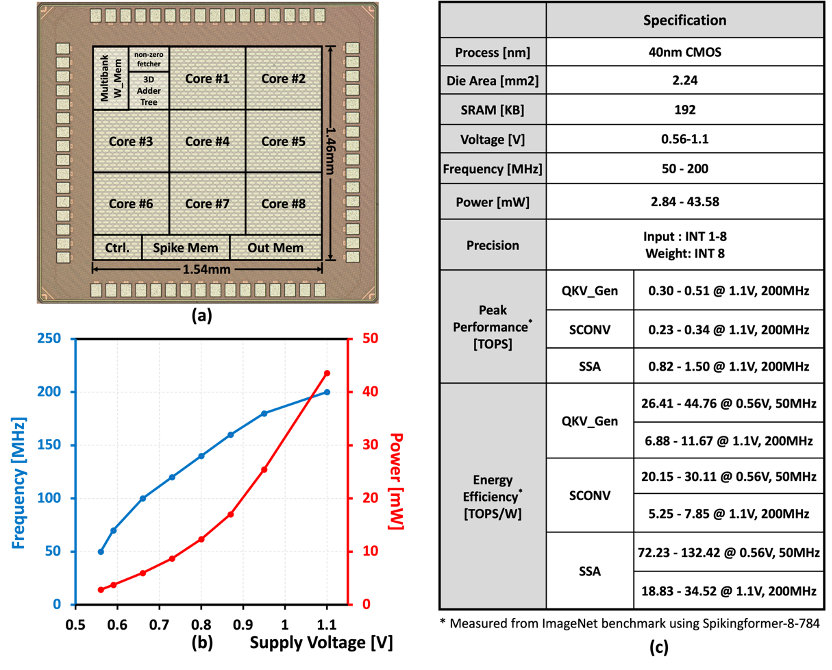
Fig.2.Die photo, Voltage-Frequency Scaling and the specification of the chip
Reference
C. Fang, Z. Shen, Z. Wang, S. Zhao, C. Wang, F. Tian, J. Yang and M. Sawan, " An Energy-Efficient Unstructured Sparsity-Aware Deep SNN Accelerator With 3-D Computation Array," IEEE Journal of Solid-State Circuits (JSSC), Nov. 2024.
More information can be found at the following link:
https://ieeexplore.ieee.org/document/10777513