Embodied Intelligence (EAI) has emerged as a crucial way for AI models to interact with the physical world. Robotic agents equipped with AI models can perform a variety of cognitive tasks.
Vision Transformers(ViT) stand out due to their superior spatio-temporal feature extraction capabilities, demonstrating the best overall performance across various embodied intelligence tasks. However, there are two main challenges for a ViT-dedicated processor for embodied intelligence.
First, the primary challenge lies in the substantial external memory access (EMA) required for feature map data. In embodied AI applications, each action decision of the robot agent depends on both the current state and historical information, necessitating the use of multiple consecutive image frames over a time window of length T as input for every inference. This large volume of input data must be read from external memory, leading to significant EMA pressure, which becomes a major bottleneck for system energy consumption and latency.
The second challenge lies in the inefficiency of the self-attention mechanism. As the core component of the Vision Transformer (ViT), the self-attention computation process requires generating an attention map of size N² as an intermediate result, where N represents the sequence length. However, the subsequent softmax operation requires accessing a complete row of the attention map each time, which forces these large intermediate results to be repeatedly transferred between on-chip and off-chip memory. This results in substantial EMA overhead and poor computational efficiency. When the EMA bandwidth is constrained or the sequence length increases, the EMA latency of self-attention becomes the bottleneck of the system.
A recent contribution from the CenBRAIN Neurotech Center of Excellence, published on the IEEE Transactions on Circuits and Systems for Artificial Intelligence (TCAS-AI). This journal paper focuses on addressing the computational and memory access challenges associated with ViT-based PVRs.
Chaoming Fang and Ziyang Shen, two Ph.D students from CenBRAIN Neurotech are co-first authors of this work, Prof. Mohamad Sawan and Dr. Jie Yang are co-corresponding authors.
This work was supported in part by the STI2030-Major Projects under Grant 2022ZD0208805, in part by the “Pioneer” and “Leading Goose” Research and Development Program of Zhejiang under Grant 2024C03002, and in part by the Key Project of Westlake Institute for Optoelectronics under Grant 2023GD004.
Abstract
This paper proposes a hardware-software co-optimized solution: a 28nm Spiking Vision Transformer Accelerator for Embodied Intelligence, featuring a Dual-Path Sparse Compute Core and an EMA-free Self-Attention Engine. At the algorithmic level, the conventional vision transformer is replaced with a spiking vision transformer, which leverages the high input sparsity of spiking neural networks (SNNs) and the efficient linear self-attention structure of spiking transformers to reduce computational complexity. At the hardware architecture level, innovative designs such as the dual-path sparse compute core, on-chip self-attention engine, and a unified multi-precision adder tree array significantly reduce memory access overhead and computational latency. Fabricated in 28nm CMOS technology, the chip has been validated across multiple embodied AI tasks. It achieves an energy consumption of 1.79mJ/frame for ViT-B inference, which is 4.1 times lower than previous work with the same model and demonstrates an overall energy efficiency of 57.7 TOPS/W, representing a 34.8% improvement over state-of-the-art vision transformer accelerators.
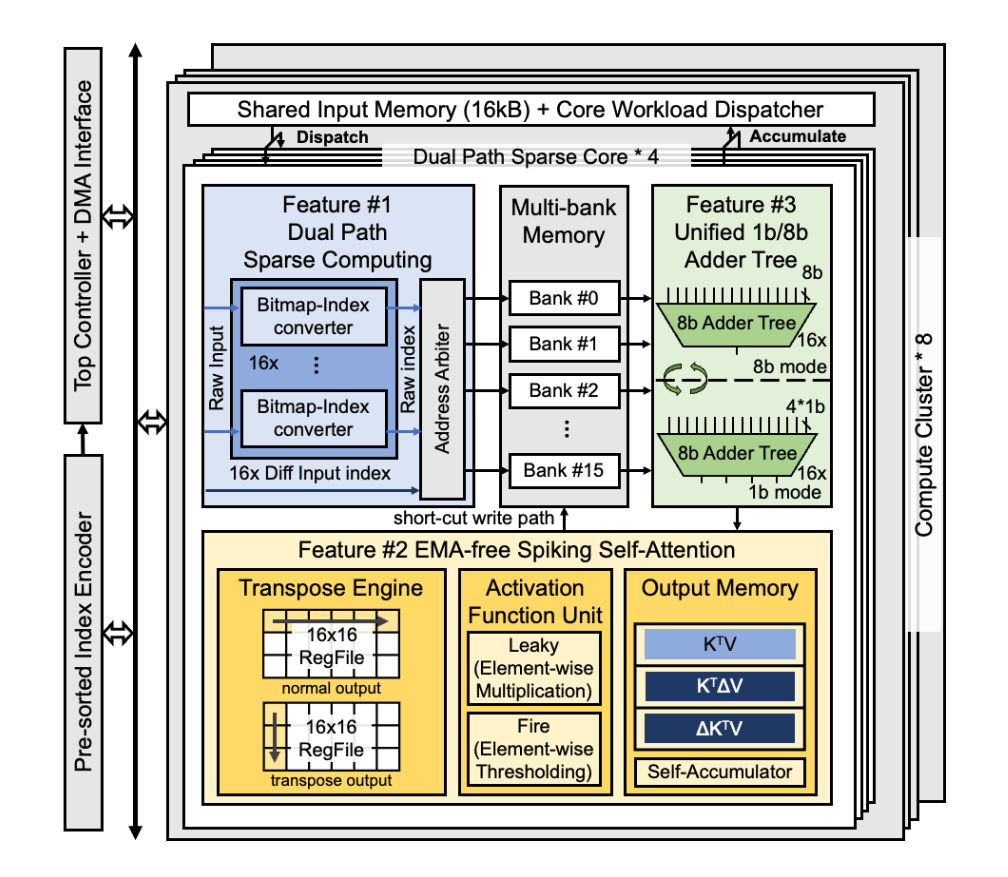
Fig.1. Overall architecture of the proposed spiking vision transformer accelerator.
图1: 本研究所提出的脉冲视觉Transformer加速器整体架构图
Research Highlights
1. This work introduces a group-wise frame differential dataflow, which utilizes one raw frame and two differential frames as input to significantly enhance input sparsity and eliminate intermediate data movement. Combined with the proposed block-level CSR compression format, this design reduces the external memory access for inputs by 58%. Additionally, a dual-path sparse compute core is designed to enable conflict-free sparse processing of both raw and differential inputs.
2. A fast, external memory access (EMA)-free spiking self-attention (SSA) scheme is proposed, which can be efficiently mapped to the presented hardware architecture. Through a set of hardware-software co-design techniques—including first-order approximation, KV-first dataflow, and a dedicated transpose engine—an EMA-free SSA computation is achieved. This scheme reduces latency by 46.5% compared to the baseline design while cutting memory space requirements by 83.6%.
3. A unified 1b/8b adder tree array is developed. Normally operating on 16×16 8-bit accumulations, this array can also be reused to perform 16×64 1-bit accumulations, improving throughput by 4× with only a 19% area overhead, thereby enabling high-throughput spiking self-attention computation.
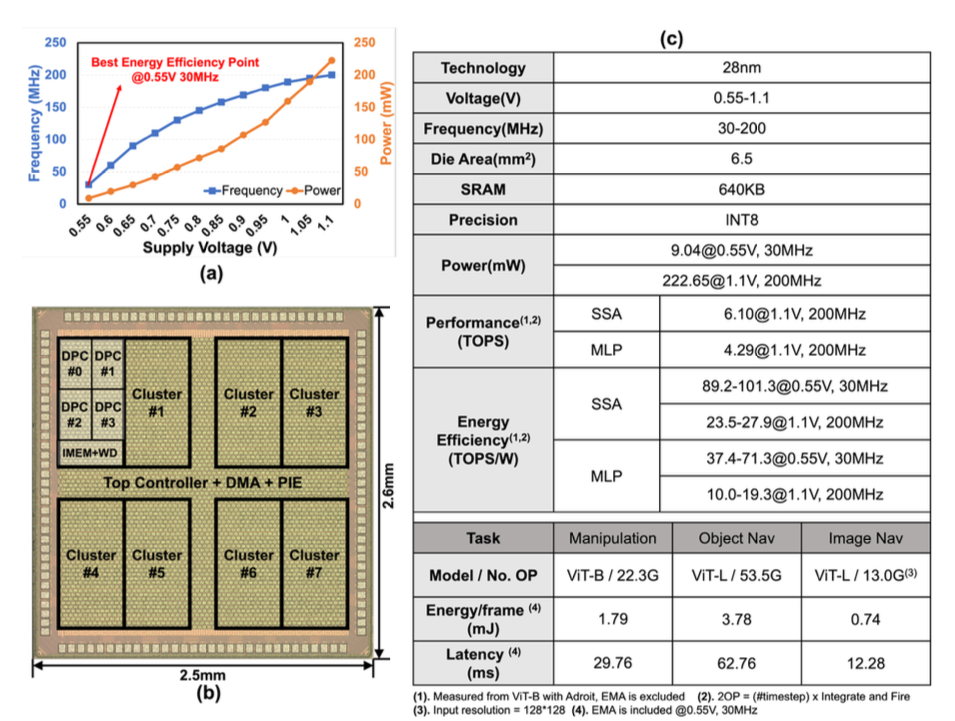
Fig.2.Die photo and the specification of the chip.
图2:芯片显微照片以及规格表
Reference
C. Fang, Z. Shen, T. Li, S. Zhao, F. Tian, J. Yang and M. Sawan, "A 28nm Spiking Vision Transformer Accelerator with Dual-Path Sparse Compute Core and EMA-free Self-Attention Engine for Embodied Intelligence," IEEE Transactions on Circuits and Systems for Artificial Intelligence (TCAS-AI), 2025.
🔍复制链接搜索全文
More information can be found at the following link:
https://ieeexplore.ieee.org/document/11124571